Google Unveils DiffusionGemma: A New Method That Could Make AI Responses Much Faster
Google released the open DiffusionGemma model, which generates text in parallel via text diffusion instead of token by token, reaching up to 4x speed on dedicated GPUs.

On June 10, 2026, Google unveiled an experimental open AI model called DiffusionGemma, which adopts a radically different way of generating text that may make responses up to four times faster on dedicated graphics cards. Google DeepMind released it in collaboration with the Gemma team under the open Apache 2.0 license, so any developer or researcher can experiment with this emerging approach known as text diffusion.
The New Idea: From Writing Letter by Letter to Painting All at Once
Most language models today — including GPT, Gemini, and Claude — rely on autoregressive generation; that is, producing text one token after another from left to right, where each token depends on the ones before it. DiffusionGemma, however, borrows its idea from image generation models: it starts from a "canvas" of 256 random tokens (noise), then gradually refines it across several passes until coherent text emerges. In this way, it generates an entire block of text at once and in parallel, instead of sequentially token by token.
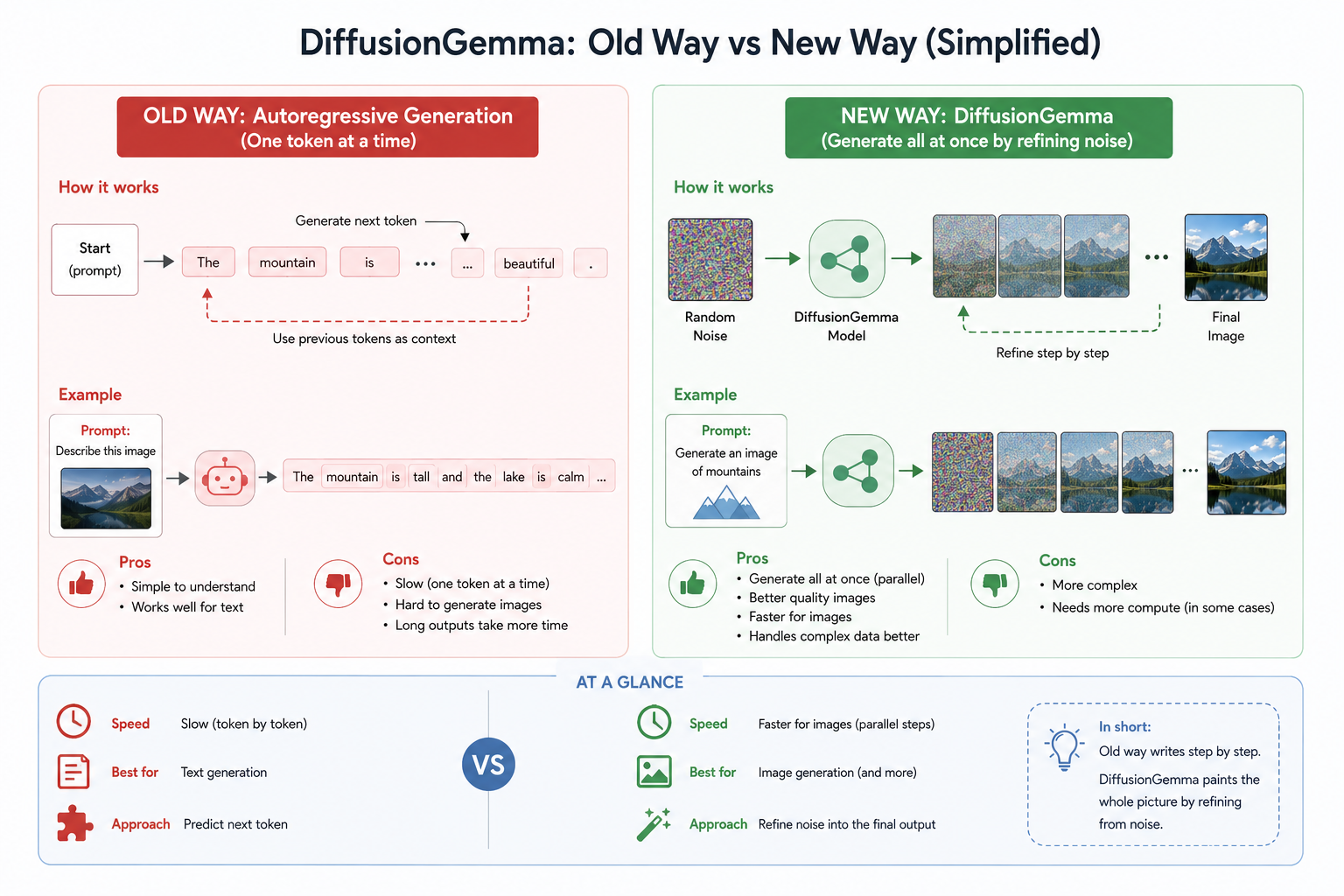
Why Is It Faster?
In traditional models, the bottleneck lies in memory bandwidth, since generating each token requires reloading the model's weights from memory. Generating parallel blocks in DiffusionGemma shifts the burden from a memory constraint to a compute-intensive operation, making more efficient use of modern GPUs and their Tensor Cores. The result: speeds up to four times that of a traditional model in single-user mode on a dedicated card, exceeding a thousand tokens per second on a single H100. NVIDIA handled the optimization side.
Technical Specifications
DiffusionGemma is a Mixture of Experts model with 26 billion total parameters, but it activates only 3.8 billion per step, as the appropriate specialized sub-networks fire depending on the input. It is built on the Gemma 4 family with a diffusion head added, and it draws its diffusion mechanism from Google's earlier Gemini Diffusion research. After quantization, the model fits within about 18 gigabytes of GPU memory, allowing it to run on high-end consumer cards without needing massive servers or a cloud account. It also supports a 256K-token context window, more than 140 languages, and multimodal inputs including text, image, and video.
A Unique Capability: Real-Time Self-Correction
Because the model generates the entire block via bidirectional attention, it reads the context of the whole paragraph while denoising. If it notices a logical or grammatical error at the start of the block, it can rewrite and correct it in real time before delivering the final text, and even format complex Markdown on the fly. This capability makes it particularly suited to "non-linear" tasks that confuse traditional models, such as inserting text earlier in a passage or filling gaps in program code.
Limitations to Note
In fairness, DiffusionGemma is an experimental model, and the quality of the text it generates is lower compared to traditional models at present. The speed advantage is also realized mainly in single-user mode on dedicated cards, not in every deployment scenario. The model is aimed more at developers and researchers interested in speed-critical local interactive tasks, rather than as a general replacement for advanced models.
The Significance of the Step in the Longer Term
Text diffusion models are not entirely new; earlier models like LLaDA in 2025 proved the idea viable, but they remained confined to labs without sufficient infrastructure support. What distinguishes DiffusionGemma is that it arrives with day-zero support across multiple development frameworks; the vLLM team even built a new software abstraction specifically to accommodate the model's non-autoregressive inference loop, an engineering investment signaling an intent to keep diffusion models in the production conversation going forward. Official llama.cpp support is planned for a future release.
Conclusion
DiffusionGemma is a bet by Google that parallel text generation may reshape the economics of local AI, shifting the burden from the costly cloud to hardware within developers' reach. Although it is still experimental and its quality is below mature models, the fact that it is open and supported from launch makes it fertile ground for experimentation. For the developer interested in running models locally or in fast interactive tasks, DiffusionGemma is worth following closely.
Newsletter
Enjoyed this?
Subscribe and get every new article and news post straight to your inbox.


