Google تكشف DiffusionGemma: طريقة جديدة قد تجعل ردود الذكاء الاصطناعي أسرع بكثير
أطلقت Google نموذج DiffusionGemma المفتوح الذي يولّد النص بالتوازي عبر انتشار النص بدل رمز برمز، محقّقًا سرعة تصل إلى 4 أضعاف على بطاقات الرسوميات المخصّصة.

كشفت Google يوم العاشر من يونيو 2026 عن نموذج ذكاء اصطناعي تجريبي مفتوح باسم DiffusionGemma، يتبنّى طريقة مختلفة جذريًا في توليد النص قد تجعل الردود أسرع بأربعة أضعاف على بطاقات الرسوميات المخصّصة. وأطلقته Google DeepMind بالتعاون مع فريق Gemma تحت رخصة Apache 2.0 المفتوحة، ليتمكّن أي مطوّر أو باحث من تجربة هذا النهج الناشئ المعروف بـ«انتشار النص» (Text Diffusion).
ما الفكرة الجديدة؟ من الكتابة بحرف إلى الرسم دفعة واحدة
تعتمد معظم النماذج اللغوية اليوم — بما فيها GPT وGemini وClaude — على التوليد «الانحداري الذاتي» (Autoregressive)؛ أي إنتاج النص رمزًا تلو الآخر من اليسار إلى اليمين، حيث يعتمد كل رمز على ما سبقه. أما DiffusionGemma فيستعير فكرته من نماذج توليد الصور: يبدأ من «لوحة» مكوّنة من 256 رمزًا عشوائيًا (ضوضاء)، ثم ينقّيها تدريجيًا عبر عدّة تمريرات حتى يظهر نصّ مفهوم. بهذا يولّد كتلة كاملة من النص في وقت واحد وبالتوازي، بدل التسلسل رمزًا برمز.
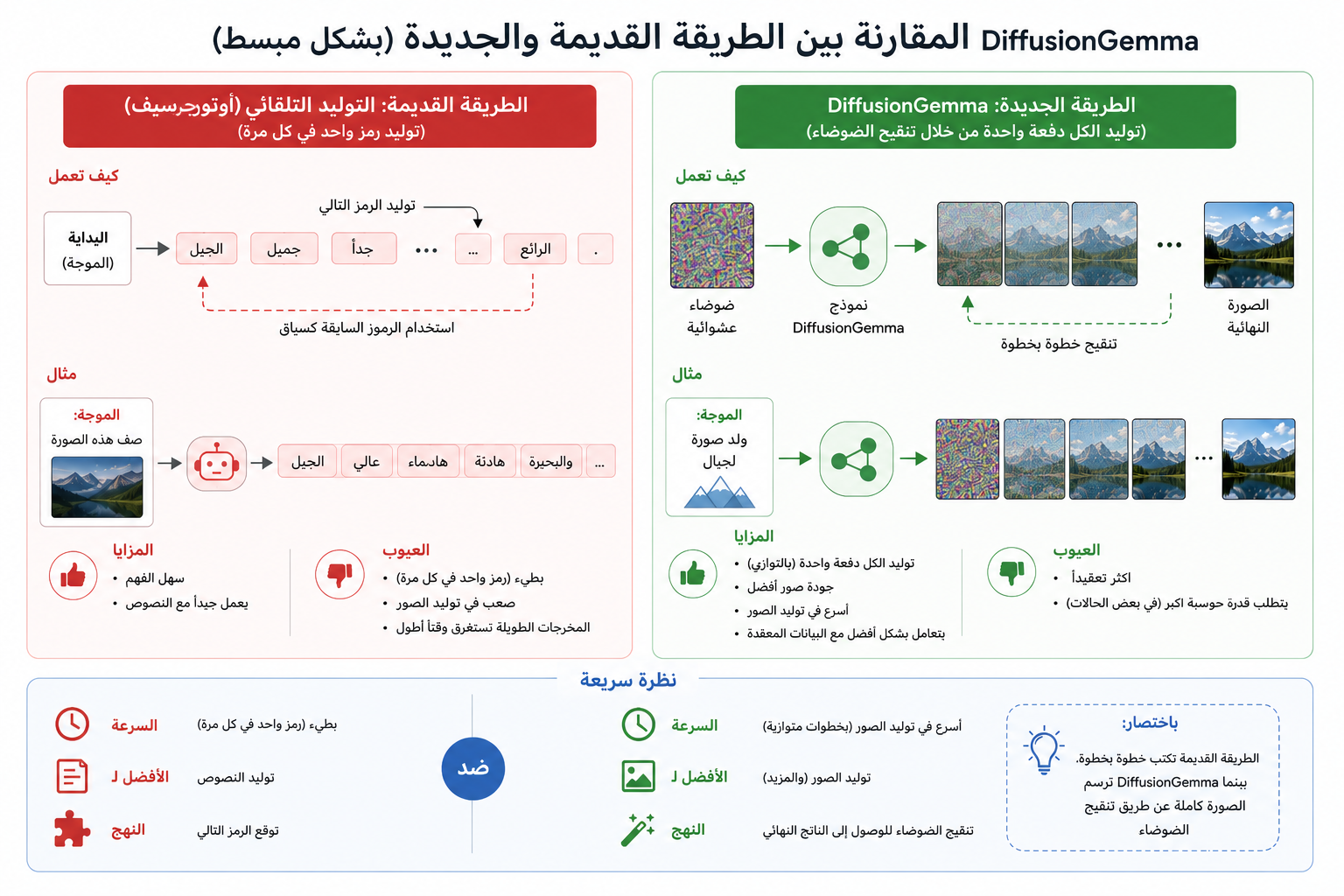
لماذا يكون أسرع؟
في النماذج التقليدية، يكمن عنق الزجاجة في عرض نطاق الذاكرة (Memory Bandwidth)، إذ يتطلّب توليد كل رمز إعادة تحميل أوزان النموذج من الذاكرة. أما توليد كتل متوازية في DiffusionGemma فيحوّل العبء من قيد الذاكرة إلى عملية حسابية مكثّفة، ما يستغل معالجات الرسوميات الحديثة وأنويتها (Tensor Cores) بكفاءة أعلى. النتيجة: سرعة تصل إلى أربعة أضعاف النموذج التقليدي في وضع المستخدم الواحد على بطاقة مخصّصة، وتجاوز ألف رمز في الثانية على بطاقة H100 واحدة. وقد تولّت NVIDIA جانب التحسين (Optimization).
المواصفات التقنية
DiffusionGemma نموذج بمعمارية «مزيج الخبراء» (Mixture of Experts) يبلغ إجمالي معاملاته 26 مليارًا، لكنه يُفعّل 3.8 مليار فقط في كل خطوة، إذ تعمل الشبكات الفرعية المتخصّصة المناسبة حسب المُدخل. وهو مبني على عائلة Gemma 4 مع إضافة «رأس انتشار» (Diffusion Head)، ويستلهم آلية الانتشار من أبحاث Google السابقة في Gemini Diffusion. وبعد تقليل دقّته (Quantization)، يتّسع النموذج في نحو 18 جيجابايت من ذاكرة الرسوميات، ما يتيح تشغيله على بطاقات المستهلكين المتطوّرة دون الحاجة إلى خوادم ضخمة أو حساب سحابي. كما يدعم نافذة سياق تبلغ 256 ألف رمز، وأكثر من 140 لغة، ومدخلات متعدّدة الوسائط تشمل النص والصورة والفيديو.
قدرة فريدة: التصحيح الذاتي الآني
لأن النموذج يولّد الكتلة كاملة عبر «انتباه ثنائي الاتجاه» (Bidirectional Attention)، فهو يقرأ سياق الفقرة بأكملها أثناء تنقية الضوضاء. وإذا لاحظ خطأ منطقيًا أو نحويًا في بداية الكتلة، يستطيع إعادة كتابته وتصحيحه آنيًا قبل إخراج النص النهائي، بل وتنسيق صياغات Markdown المعقّدة في الوقت الفعلي. هذه القدرة تجعله مناسبًا تحديدًا للمهام «غير الخطّية» التي تربك النماذج التقليدية، مثل إدراج نص في مكان سابق أو ملء فجوات في شيفرة برمجية.
قيود يجب الانتباه إليها
من الإنصاف القول إن DiffusionGemma نموذج تجريبي، وإن جودة النص الذي يولّده أقلّ مقارنةً بالنماذج التقليدية في الوقت الراهن. كما أن ميزة السرعة تتحقّق أساسًا في وضع المستخدم الواحد على بطاقات مخصّصة، لا في كل سيناريوهات التشغيل. فالنموذج موجّه أكثر للمطوّرين والباحثين المهتمّين بالمهام التفاعلية المحلّية الحسّاسة للسرعة، لا كبديل عام عن النماذج المتقدّمة.
أهمية الخطوة على المدى الأبعد
نماذج انتشار النص ليست جديدة كليًا؛ فقد أثبتت نماذج سابقة مثل LLaDA عام 2025 جدوى الفكرة، لكنها بقيت حبيسة المختبرات دون دعم بنية تحتية كافٍ. ما يميّز DiffusionGemma أنه يأتي بدعم فوري عبر أطر تطوير متعدّدة منذ يومه الأول، حتى إن فريق vLLM بنى تجريدًا برمجيًا جديدًا خصيصًا لاستيعاب حلقة الاستدلال غير الانحدارية للنموذج، وهو استثمار هندسي يشير إلى نيّة إبقاء نماذج الانتشار حاضرة في نقاش الإنتاج مستقبلًا. ودعم llama.cpp الرسمي مخطّط لإصدار لاحق.
خلاصة
DiffusionGemma رهان من Google على أن توليد النص بالتوازي قد يعيد تشكيل اقتصاديات الذكاء الاصطناعي المحلّي، بنقل الأعباء من السحابة المكلِّفة إلى أجهزة في متناول المطوّرين. ورغم أنه ما زال تجريبيًا وجودته أدنى من النماذج الناضجة، فإن كونه مفتوحًا ومدعومًا منذ انطلاقه يجعله أرضًا خصبة للتجربة. وبالنسبة للمطوّر العربي المهتمّ بتشغيل النماذج محلّيًا أو بالمهام التفاعلية السريعة، يستحقّ DiffusionGemma متابعة عن قرب.
النشرة البريدية
أعجبك المحتوى؟
اشترك ليصلك كل جديد من المقالات والأخبار في بريدك مباشرةً.


